Can a Semantic Kumo Wrestle Google?
Can a semantic kumo wrestle Google to the mat? This deep dive explores the potential of a semantic kumo, a new approach to information retrieval, and compares it to Google’s dominant search engine. We’ll examine its strengths, weaknesses, and potential impact on the future of search. The comparison delves into how this innovative technology might redefine how we find information online.
We’ll unpack the core functionalities of a semantic kumo, highlighting its unique ability to understand context and meaning beyond simple s. We’ll contrast this with Google’s existing architecture, analyzing its strengths and weaknesses in handling various types of information. This exploration will reveal potential areas of competition, from handling complex queries to tailoring results to individual users. The discussion further explores the ethical considerations, including data privacy implications, and potential challenges in implementation.
Defining Semantic Kumo and Google’s Role
A “semantic kumo,” a hypothetical system, aims to revolutionize information retrieval by understanding the meaning behind words and concepts, rather than simply matching s. This approach, rooted in semantic web technologies, promises a more nuanced and accurate way to find information, potentially surpassing the limitations of current -based search engines. Conversely, Google, with its vast data and sophisticated algorithms, has dominated the information retrieval landscape for years, achieving impressive accuracy in matching user queries with relevant results.
This comparison explores the contrasting approaches and the potential of semantic kumo to challenge Google’s dominance.Semantic kumo, at its core, is a system designed to understand the semantic relationships between data points. It uses advanced natural language processing (NLP) and knowledge graphs to establish contextual connections. This means understanding the meaning of a query, not just its s.
Imagine searching for “best running shoes for marathon training.” A semantic kumo would understand that this query relates to performance, comfort, durability, and specific running metrics, potentially leading to results tailored to the user’s precise needs, rather than just generic listings of running shoes. Potential applications extend far beyond simple searches, including personalized recommendations, automated summarization of complex documents, and even sophisticated question-answering systems.
Semantic Kumo’s Core Functionalities
Semantic kumo leverages a range of semantic web technologies, such as ontologies and semantic triples, to create a comprehensive knowledge graph. This knowledge graph establishes relationships between different concepts, enabling the system to understand the nuances of a query and return results that are highly relevant to the user’s intent. It is crucial to understand that these technologies allow the system to move beyond simple matching, enabling it to connect concepts with their meaning and context.
Google’s Search Engine Architecture
Google’s search engine architecture is built on a foundation of massive data indexing and complex algorithms. The system relies heavily on matching and PageRank, a ranking algorithm that assesses the importance of web pages based on the number and quality of links pointing to them. While effective in finding relevant documents, this approach can struggle with nuanced queries or complex concepts.
This -based approach is successful in many cases, but it struggles with nuanced queries, especially when dealing with intricate concepts.
Comparison of Approaches
| Feature | Google’s Approach | Semantic Kumo’s Approach ||—|—|—|| Information Processing | Primarily -based, matching user queries to indexed web pages. | Understanding the meaning of user queries and contextual relationships, utilizing semantic web technologies to connect concepts. || Query Understanding | Relies on matching and statistical analysis. | Employs NLP and knowledge graphs to grasp the semantic meaning of queries.
|| Result Relevance | High relevance for simple queries, but may struggle with complex concepts. | Potentially higher relevance for complex queries, aiming for a more comprehensive and nuanced understanding of user needs. || Scalability | Proven scalability, handling massive datasets effectively. | Scalability is a key challenge, requiring efficient algorithms and optimized data structures. |
Key Concepts of Semantic Web Technologies
Semantic web technologies provide the underpinning for semantic kumo’s capabilities. These technologies focus on representing information in a way that computers can understand, rather than just humans. This includes the use of ontologies, which define concepts and relationships between them, and semantic triples, which express facts in a standardized format. These allow the system to move beyond matching, allowing it to link concepts to their meaning and context.
For example, an ontology could define the concept of “running shoes” and its properties, including “material,” “price,” and “performance metrics.”
Strengths and Weaknesses
| Feature | Semantic Kumo | |
|---|---|---|
| Strengths | Proven scalability, vast dataset, high accuracy for simple queries, established infrastructure. | Potential for higher relevance for complex queries, nuanced understanding of user intent, more comprehensive results, personalized experiences. |
| Weaknesses | Struggles with complex queries, limited ability to grasp semantic meaning, can provide irrelevant or superficial results. | Scalability challenges, computational complexity, potential for errors in semantic interpretation, requires substantial investment in data and infrastructure. |
Potential Areas of Competition
A semantic kumo, with its focus on understanding the nuances of language and context, presents a compelling alternative to Google’s current search paradigm. While Google excels at indexing and retrieving vast amounts of information, its reliance on matching can sometimes lead to irrelevant or less-than-ideal results, especially for complex or nuanced queries. A semantic kumo, by contrast, aims to grasp the underlying meaning and intent behind a user’s request, offering a potentially superior user experience.
Potential Areas of Outperformance
A semantic kumo could significantly outperform Google in specific information retrieval tasks. Its ability to interpret context, understand relationships between concepts, and leverage user data provides a strong foundation for delivering more accurate and tailored results. For example, a user searching for “best Italian restaurants near me with vegetarian options” could benefit from a kumo that understands the interconnectedness of these search terms and dynamically filters results to prioritize vegetarian-friendly restaurants located within a specified proximity.
So, can a semantic kumo really take down Google? It’s a fascinating question, but the sheer scale of Google’s search dominance feels daunting. YouTube, though, is showing a willingness to disrupt the status quo by building new distribution channels for content, like youtube builds new pipes for tv shows movies. This might suggest that other players are finding innovative ways to compete, perhaps even in the semantic search arena.
Ultimately, the answer to whether a semantic kumo can wrestle Google to the mat remains uncertain, but the evolving landscape of online content distribution is definitely interesting.
Information Retrieval Tasks
Semantic kumo excels at tasks where context and relationships are crucial. Consider queries involving complex concepts, or those requiring a deep understanding of the connections between various ideas. Imagine a user searching for “how the discovery of penicillin impacted the development of antibiotics,” – a kumo could not only identify relevant documents discussing penicillin but also highlight the subsequent evolution of antibiotic research and development.
This nuanced understanding of complex topics is a potential area where a kumo would surpass Google’s -based approach. Furthermore, a kumo could handle niche queries more effectively, such as finding specific historical documents about a forgotten scientific experiment, by understanding the semantic links between seemingly disparate terms.
Leveraging User Data for Tailored Results
By meticulously tracking user interactions, a semantic kumo can dynamically adjust its search algorithms to provide increasingly personalized results. For instance, if a user frequently searches for information related to sustainable agriculture, the kumo could begin to present results emphasizing environmentally conscious practices and farming techniques. This adaptive learning process leads to more tailored and relevant search results over time, unlike Google’s relatively static -matching algorithm.
Superior User Experience Use Cases
| Search Query | Google’s Potential Outcome | Semantic Kumo’s Potential Outcome ||—|—|—|| “Best hiking trails near Yosemite with elevation gain under 1000ft” | Might return trails with elevation gain over 1000ft, or irrelevant results | Prioritizes trails meeting the elevation criteria and filters based on proximity to Yosemite || “Explain the difference between a supernova and a nebula” | Might provide a general overview of both but fail to highlight the causal relationship | Presents a detailed explanation of the evolutionary connection, showing how a supernova forms a nebula || “What are the economic implications of the recent government policy changes?” | Might return general news articles without analyzing specific economic impact | Summarizes the policy changes and connects them to their economic consequences, potentially including projections or historical parallels || “Find research papers on the correlation between sleep deprivation and cognitive function in adolescents” | Might return a mix of papers about sleep and cognitive function but not specifically focusing on adolescents | Returns only research papers directly addressing the correlation in adolescents, presenting results in a user-friendly format |
Handling Niche and Complex Queries
A semantic kumo has the potential to handle niche and complex queries with greater success than Google’s current approach. Consider a query like “find historical accounts of the use of medicinal plants in the Amazon rainforest during the pre-Columbian era.” A kumo, capable of understanding the interconnectedness of terms like “medicinal plants,” “Amazon rainforest,” and “pre-Columbian era,” could efficiently retrieve relevant historical documents and anthropological studies, providing a comprehensive response to the user’s request.
This ability to tackle complex and nuanced inquiries is a significant advantage in specific domains.
Semantic Kumo’s Strengths and Weaknesses
Semantic Kumo, a hypothetical system leveraging semantic web technologies, promises a powerful approach to information retrieval. Its ability to understand context and relationships between data points could revolutionize how we access and utilize information. However, inherent challenges exist, including scalability, data management, and potential biases. Understanding these strengths and weaknesses is crucial to assessing the system’s viability and potential impact.
Information Retrieval and Contextual Understanding
Semantic Kumo excels at extracting meaning from unstructured data. By using ontologies and knowledge graphs, it can connect seemingly disparate pieces of information, revealing hidden relationships and patterns. This contextual understanding allows for more precise and relevant information retrieval compared to traditional -based search. For instance, a query about “climate change solutions” could not only return articles discussing specific technologies but also highlight the interconnectedness of energy production, agricultural practices, and policy changes.
This contextual understanding enhances the user experience by delivering more insightful and comprehensive results.
Scalability, Data Management, and Potential Biases
One of the key challenges facing Semantic Kumo is scalability. Handling vast quantities of data and ensuring efficient processing of complex queries is a significant hurdle. Data management is another critical concern. Maintaining accuracy, consistency, and completeness of the underlying knowledge graph is crucial. Inaccurate or incomplete data can lead to flawed results.
Additionally, the knowledge graph itself could potentially reflect existing biases in the data used to build it. This could lead to skewed results and reinforce societal prejudices. For example, if the data used to build the knowledge graph disproportionately represents the opinions of a particular group, the results may unfairly favor that perspective.
Shortcomings in Current Semantic Web Technologies
Current semantic web technologies face limitations in areas such as reasoning and inference. Semantic Kumo’s success hinges on the ability of these technologies to accurately interpret and combine complex information. Inconsistencies and ambiguities in existing ontologies and knowledge graphs can lead to errors in reasoning. This can hinder the development of a fully robust and reliable Semantic Kumo.
For example, the different interpretations of “climate change” in various academic disciplines can lead to a lack of consensus in a knowledge graph. This lack of consensus can make it difficult to identify and connect relevant data points accurately.
Pros and Cons of Using Semantic Kumo
| Pros | Cons |
|---|---|
| Improved accuracy and relevance of search results due to contextual understanding. | Scalability challenges in handling large volumes of data. |
| Enhanced ability to identify hidden relationships and patterns in data. | Potential for biases in results if the underlying data is biased. |
| Ability to integrate and connect disparate data sources. | Dependency on the accuracy and completeness of the knowledge graph. |
| Potential for more comprehensive and insightful information retrieval. | Challenges in maintaining consistency and accuracy of the knowledge graph over time. |
| More sophisticated understanding of complex topics. | Potential for increased complexity in query formulation. |
Ethical Implications of Personal Data Analysis
Using Semantic Kumo for personal data analysis raises critical ethical concerns about privacy. The system’s ability to analyze personal data and uncover patterns could lead to a violation of user privacy if not handled with utmost care. Furthermore, the potential for misuse of this data for targeted advertising or manipulation is significant. Strict regulations and ethical guidelines are necessary to mitigate these risks and protect user privacy.
For example, if a user’s browsing history is used to predict their future needs and preferences, it could potentially influence their choices in ways that are not beneficial to them.
Can a semantic kumo truly challenge Google’s dominance? It’s a fascinating question, and the sheer volume of data required for a successful semantic kumo likely presents its own set of challenges. With great amounts of data comes great responsibility, and effectively utilizing and curating that data is key to any meaningful competitor emerging. Ultimately, whether a semantic kumo can truly wrestle Google to the mat depends heavily on its ability to handle the complexity and ethical considerations inherent in managing massive datasets, much like the considerations discussed in with great amounts of data comes great responsibility.
The race to build a superior semantic knowledge base is certainly on.
Competitive Landscape and Future Prospects: Can A Semantic Kumo Wrestle Google To The Mat
The search engine landscape is dominated by Google, but the quest for better information retrieval methods continues. Semantic Kumo, with its focus on understanding context and nuance, presents a potential challenger. Understanding the current competitive landscape, potential future developments, and the hurdles to overcome is crucial for evaluating Semantic Kumo’s viability.The current search engine market is highly competitive, with Google holding a dominant position.
However, alternative search engines and specialized platforms are gaining traction, focusing on specific niches, user groups, or improved functionalities. Understanding the strengths and weaknesses of existing players, and identifying gaps in the market, is vital for Semantic Kumo to succeed.
Current Search Engine Landscape
The search engine market is dominated by Google, which holds a significant market share and a strong brand recognition. Other major players, like Bing, DuckDuckGo, and specialized search engines catering to specific domains (e.g., academic research), exist. These competitors offer various functionalities and user experiences, appealing to different user needs.
Key Competitors to Google
Several companies challenge Google’s dominance in search. Bing, powered by Microsoft, offers a comparable search experience. DuckDuckGo prioritizes user privacy, aiming to provide results without tracking user activity. Specialized search engines, like those dedicated to academic research or legal information, cater to specific user groups with specialized needs. These examples highlight the diverse landscape beyond Google’s core search offering.
Future of Information Retrieval
The future of information retrieval will likely be increasingly focused on context, meaning, and user intent. Semantic Kumo’s ability to understand complex queries and provide tailored results, based on deeper semantic understanding, positions it well in this evolving landscape. This trend is evident in the rise of AI-powered assistants and the growing demand for personalized information experiences. The increasing use of natural language processing (NLP) and machine learning in search engines exemplifies this trend.
Challenges for Developing and Implementing Semantic Kumo
Developing and implementing Semantic Kumo faces significant hurdles. The complexity of natural language understanding, the vastness of the data needed to train the system, and the need to maintain accuracy and relevance in the face of constantly evolving information are key challenges. Successfully scaling the system to handle a large volume of queries while maintaining speed and efficiency is another crucial concern.
Opportunities for Semantic Kumo
Semantic Kumo presents several opportunities. By focusing on context-aware search, it can address the limitations of traditional -based searches. This allows it to provide more accurate and relevant results, tailored to individual user needs. Semantic Kumo has the potential to improve user experience and satisfaction. It also has the potential to disrupt existing search engine models by offering a fresh approach to information retrieval.
User Experience and Design
User experience and design are crucial for Semantic Kumo’s success. A user-friendly interface, intuitive navigation, and clear presentation of results are essential for engagement and satisfaction. The design should prioritize ease of use and clarity, helping users efficiently access the information they need. An effective design will address the potential complexity of a semantic search system, ensuring a positive user experience.
While a semantic “kumo” might challenge Google’s search dominance, the real disruption might come from unexpected places. Consider California’s recent fertility regulations and the implications for reproductive technology, like those discussed in calif s fertility flap and the future of reproductive tech. These advancements, while not directly about semantic search, could fundamentally change how we interact with information, potentially reshaping the very landscape that Google inhabits.
Ultimately, the question of whether a semantic kumo can topple Google remains a complex one.
Potential Future Developments in Semantic Kumo and Search Engine Market Impact
| Development | Impact on Search Engine Market ||—|—|| Enhanced semantic understanding | Improved accuracy and relevance of search results, leading to increased user satisfaction and potentially impacting market share. || Integration with AI assistants | Enhanced user experience, enabling seamless information access through diverse platforms. || Improved user interfaces | Increased user engagement, potentially driving adoption of the Semantic Kumo platform.
|| Scalability of the system | Ability to handle large volumes of queries, maintaining speed and efficiency, crucial for broad market adoption. || Data security and privacy | Trust and reliability, ensuring user data is handled securely and ethically, influencing adoption decisions. |
Illustrative Examples and Scenarios

A semantic kumo, unlike traditional search engines, aims to understand the nuances and context of user queries. This approach allows for more precise and relevant results, particularly in complex domains. This section delves into practical scenarios demonstrating how a semantic kumo might function and evolve through user interaction.
Legal Domain Example
A user searches for “cases involving intellectual property infringement in the software industry after 2015.” A traditional search engine might return a vast list of documents, many irrelevant. A semantic kumo, however, would understand the key concepts – intellectual property, software, infringement, and post-2015 – and prioritize results matching these criteria. It would filter for legal cases, and even highlight relevant clauses and precedents within the documents.
Scientific Query Example
Imagine a scientist querying “recent advancements in gene editing techniques impacting CRISPR-Cas9 applications.” A semantic kumo would not only return relevant research papers but also highlight key findings, potential applications, and related research groups. Crucially, it could identify potential conflicts of interest or limitations within the cited papers, providing a more comprehensive understanding of the topic.
Financial Scenario Example
A user seeks “investment opportunities in renewable energy sectors with a low carbon footprint.” A semantic kumo would analyze the user’s past searches and investment history to personalize the results. It could present tailored investment recommendations based on the user’s risk tolerance and financial goals. It would also integrate real-time market data and news related to renewable energy companies.
User Interaction and Refinement
A semantic kumo learns and adapts through user interactions. For instance, if a user frequently searches for “Italian cuisine recipes” and consistently clicks on recipes with specific ingredients (e.g., “tomato sauce”, “basil”), the kumo will understand their preferences and start prioritizing recipes containing these ingredients. This iterative refinement of results enhances the user experience and provides increasingly personalized results.
Hypothetical Search Result Page
Imagine searching for “best running shoes for marathon training.” A semantic kumo’s result page wouldn’t just list links. It would present a curated list of shoes, each accompanied by a detailed comparison table, user reviews, expert recommendations, and even suggested training plans. Visual elements, like graphs showing cushioning and support, would further enhance comprehension.
Platform Integration, Can a semantic kumo wrestle google to the mat
A semantic kumo could seamlessly integrate into existing platforms like social media. Imagine a user posting about “best coffee shops near me.” The semantic kumo could automatically suggest relevant coffee shops based on user location and past searches, thereby enhancing social interaction and providing a more personalized experience. Similar integration could happen in e-commerce platforms, where the kumo could personalize product recommendations.
Google vs. Semantic Kumo Comparison (Example Query)
| Query | Google Results | Semantic Kumo Results |
|---|---|---|
| “Impact of AI on job market” | A mix of news articles, blog posts, and research papers; some lack specific focus or context. | A curated list of peer-reviewed studies, industry reports, and expert opinions. Results are categorized (e.g., sectors most affected, future implications). A visual representation of job losses vs. new job creation is included. |
Concluding Remarks
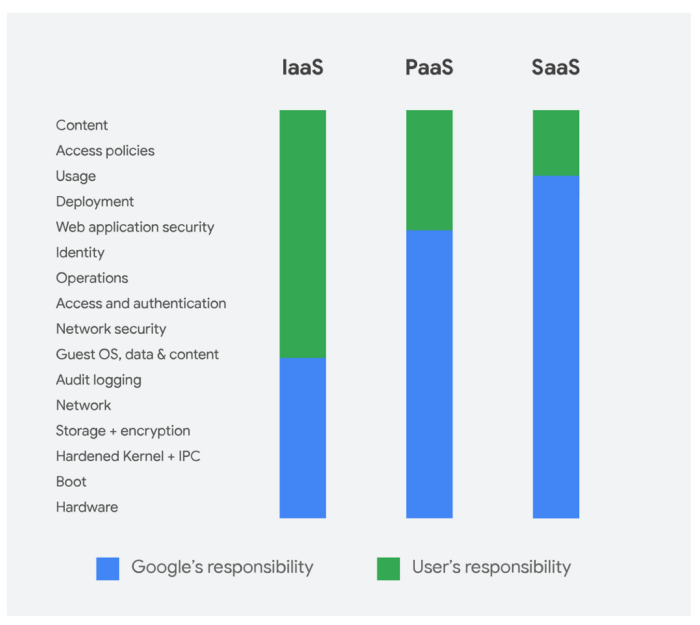
Ultimately, the question of whether a semantic kumo can dethrone Google remains open. While the technology shows promise in certain areas, significant hurdles remain, including scalability, data management, and bias mitigation. The future of information retrieval is likely a blend of existing and emerging technologies, and a semantic kumo could carve out a niche. This discussion highlights the dynamic nature of search engine technology and the ongoing quest for more effective and nuanced ways to access information.